操作系统
操作系统
聊聊 Linux 的 5 种 IO 模型
Linux IO 模型讲的是数据如何从硬盘读取到程序的内存中。整个过程其实可以分为两个阶段,分别是:从硬盘读取到内核空间,从内核空间读取到程序缓冲区。
Linux 根据这两个阶段是否阻塞,分成了 5 个经典的 IO 模型,分别是:
- 阻塞 IO 模型
- 非阻塞 IO 模型
- IO 复用模型
- 信号驱动 IO 模型
- 异步 IO 模型
这 5 种经典的 IO 模型,他们的特点是:
- 阻塞 IO 模型。 阻塞 IO 模型表示数据从硬盘到程序内存的两个阶段都会阻塞等待。
- 非阻塞 IO 模型。 非阻塞 IO 模型比起阻塞 IO 模型好一点,其在数据从硬盘到内核空间时不阻塞,而是不断地重试判断数据是否准备好。这时虽然没有阻塞,但是 CPU 还是在不断空转的。
- IO 复用模型。 IO 复用模型比起非阻塞 IO 模型,有了更进一步的提升。其可以操作不止一个文件,而是可以操作多个文件,这就是「复用」这个词的含义。比起非阻塞 IO 模型,其不断地轮询多个文件,哪个文件准备好了,就去将哪个文件从内核空间复制到用户空间。
- 信号驱动 IO 模型。 信号驱动 IO 模型比起 IO 复用模型,在硬盘到内核空间这一阶段,有了质的飞跃。系统再也不阻塞,也不轮询了,而是等文件数据复制到内核空间后,通过回调信号通知系统。从而真正实现了第一阶段的非阻塞。但信号驱动在第二阶段(内核空间到用户空间)还是阻塞的。
- 异步 IO 模型。 上面的四种模型,其第二阶段,即内核空间到用户中间都是阻塞的。但异步 IO 模型则是完全异步进行的,即两个阶段完全实现了信号回调,不存在任何阻塞。
聊聊 IO 多路复用的三种实现(select、poll、epoll模型)
Linux 有 5 种 IO 模型,其中有一种叫做 IO 多路复用模型,即其可以在第一阶段(硬盘到内核空间)通过轮询的方式实现多个文件读取,从而提高效率。而在系统层面,IO 多路复用有三种实现,分别是:select 模型、poll 模型、epoll 模型。
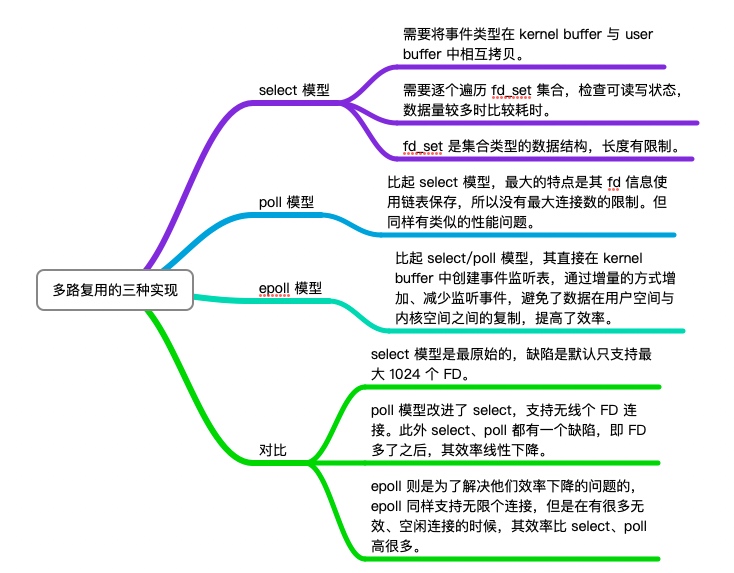
select 模型
其指的是进程想要监听哪些事件,那么就要把对应的事件放入文件描述符数组中,之后传给内核空间。内核收到文件描述符数组之后,一个个去扫描对应文件描述符的事件是否发生。当下次需要再监听同样的事件时,需要再重复同样的动作。
select 模型有很多缺点,例如:
- 需要将事件类型在内核空间与用户空间相互拷贝。
- 需要逐个遍历文件描述符集合,检查读写状态,数据量较多的时候比较耗时。
- 文件描述符集合是数组结构,长度有限制。
poll模型
而 poll 模型,其使用了链表来保存文件描述符,从而解决了 select 模型文件描述符的限制。但其他方面与 select 模型相同。
epoll模型
而 epoll 模型,则是质的突破。其直接在内核空间中创建事件监听表,通过增量的方式增加、减少监听事件,避免了数据在用户空间与内核空间的复制,提高了效率。此外,当事件发生时,直接通过回调放入队列,通知应用进程。
总结一下:
- select 模型有数据复制效率问题、查找遍历效率低、最大文件描述符的限制。
- poll 模型,解决了最大描述符的问题。
- epoll 模型,解决了最大描述符的问题、数据复制问题、通过回调解决遍历效率问题。
聊聊对 zero-copy 的理解?
zero-copy(零拷贝),从其名字就可以知道,它就是指 CPU 不需要将数据从一处拷贝到另一处。要明白 zero-copy,我们就必须清楚操作系统读取一个文件的流程。
操作系统读取一个文件的流程为:磁盘到内核空间、内核空间到用户空间、用户空间到 socket buffer、socket 缓冲区到网卡。可以看到在这个流程中,我们需要经历 2 次 CPU 拷贝,4 次内核态和用户态的 CPU 上下文切换,非常耗费时间。
而 zero-copy 其实就是指,其可以将数据直接从内核缓冲区写入网卡,而不需要通过用户缓冲区和 socket 缓冲区。实际上,zero-copy 有三种不同程度的实现,分别是:mmap 内存映射实现、sendfile 实现、SG-DMA 拷贝。
mmap 内存映射实现,本质上就是节省了从内核缓冲区到用户缓冲区的 1 次 CPU 拷贝和上下文切换。sendfile 则直接不需要将文件拷贝到用户缓冲区,可以直接拷贝到 socket 缓冲区。而 SG-DMA 拷贝则可以直接将数据从内核缓冲区,考别到网卡,实现真正的零拷贝。

聊聊你对网络 IO 模型的理解
网络 IO 模型,指的是我们如何去处理网络请求的问题。在 web 服务中,一般处理 web 服务有两种架构:基于线程的架构、事件驱动模型。
基于线程的架构。 简单地说,来一个请求就开启一个独立的线程来处理。这种模式一定程度上可以提高服务器的吞吐量,但是当并发量高的时候就会出问题。主要因为:
- 因为服务器内存是有限的,创建线程需要内存。
- 另外线程切换也需要一定的开销。
- 创建和销毁线程也需要一定的代价。
事件驱动架构。 事件驱动架构,其实就是通过一系列的事件处理器来响应时间的发生,并将服务器接收连接与事件处理分离。
一般来说时间驱动模型可以分为 Reactor 模型和 Proactor 模型。其中 Reactor 模型是同步的,而 Proactor 是异步的,目前用得比较多的还是 Reactor 模型,其中 Reactor 模型可以分为四种,分别是:
- 单 Reactor 单线程模型。 就是接收请求以及事件处理都在同一线程上进行。但这样会导致连接请求阻塞。Kafka Client 就是用的这种线程模型。
- 单 Reactor 多线程模型。 这时候添加了一个事件处理线程池,将非 IO 操作交给线程池处理。Reactor 线程专注于处理连接及响应,可以提高 Reactor 线程的 IO 响应。但是在高负载、大数据量的时候,所有 IO 操作仍然由 Reactor 承担,依然有瓶颈。
- 多 Reactor 多线程模型。 这时分为 mainReactor 和 subReactor 两种,mainReactor 主要负责连接,而 subReactor 负责 IO 操作,线程池还是负责处理非 IO 操作。Netty 就是采用多 Reactor 多线程模型。Kafka Server 就是使用这种模型,是基于 Java NIO 封装的。
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。