Redis
Redis
你们的 Redis 集群是用什么高可用方案的?
Redis 集群,我们是通过 Redis Cluster 的方式去实现的。
Redis Cluster 方式,其采用了去中心化的结构,将所有 key 都映射到 16384 个哈希槽中,每个节点负责其中几个哈希槽。当需要写入一个 key 时,对其 key 进行哈希,得到其应该放到哪个位置,之后写入对应的 Redis 服务器。
当需要读取某个 key 时,可以请求任意一台服务器,服务器会判断这个 key 是否在本机器上。如果不在本机器上,那么就转发到对应的机器上获取数据,最后再回复给客户端。
每个 Redis 分片都可以设置一个 slave 节点,slave 节点会同步 master 节点的数据。当 master 节点下线时,会通过 Redis Cluster 的哨兵监控机制获知,并将 slave 节点变成 master 节点对外提供服务。一般情况下,slave 节点不对外提供服务。
如何处理本地缓存的数据一致性问题?
缓存与数据库一致性问题,本质上是因为我们引入了缓存来减轻数据库压力,从而导致了短时间内会存在缓存与数据库会不一致的问题。技术方案的抉择需要考虑业务实际情况,要根据对数据延迟的容忍程度,选择不同的解决方案。
第一种情况:如果能容忍一定的数据延迟,并发量也不高,「更新数据库,再删除缓存」是一种合适的方案。
在这种情况下,「更新数据库,再删除缓存」是一种整体成本较低的方案。为什么呢?
首先,数据库操作相对于缓存,肯定更加耗时,因此肯定要先做耗时操作,因此更新数据库需要在前面。从数据的持久性存储来看,也是首先要保证数据持久存储。其次,删除操作比起更新操作,更加轻量级,因此需要有限选择删除缓存,等下次需要的时候再去读取新数据。
第二种情况:如果无法容忍一丁点的不一致,那么只能通过锁来实现了。
例如对于 value 的操作,在要读写这条记录的时候,对其进行 redis 加锁操作,并且不要使用 slave 节点读,这样就可以完全避免这种数据不一致的问题了。除此之外,也可以搭配消息队列来实现。
简单地说,就是更新数据库或缓存失败的时候,丢一条消息到消息队列中。然后由一个线程不断地去重试,最后如果实在失败了,那就写日记或写数据库。但这样其实搞得越来越复杂了,除非是对一致性有很高的要求,否则不会这么做。
--- 下面是详细的分析,一般不会问这么深,可自己酌情阅读。 ---
第一,对数据及时性要求不是很高。
如果对数据及时性要求不高,可以忍受少数数据不一致,那么可以采用下面这种做法。
先更新缓存,再更新数据库。或者先更新数据库,再更新缓存。
先更新缓存,再更新数据库。这种做法,可能出现更新缓存,但是数据库更新失败了,那么会导致出现脏值。用户发现自己修改了的数据,又变回去了。
先更新数据库,再更新缓存。这种方式,可能出现更新了数据库,但是缓存更新失败了,这时候会用户会发现自己的更新没生效,但过一段时间之后,缓存会失效,用户也能看到修改后的值。
如果一定要选,那么选择第二种。因为比起错误的数据,延迟的数据显然更好一些。我们可以根据实际情况将失效时间设置小一些基本可以满足要求。因为毕竟更新数据库后再更新缓存失败,这种可能性真的太小了。主动更新缓存的做法,虽然简单,但是事实上缓存的数据不一定会被立刻读取到。所以每次更新无脑去更新缓存,其实会造成资源浪费。此时,我们可以用另一种方式:删除缓存。
先删除缓存,再更新数据库。或者先更新数据库,再删除缓存。
比起主动更新缓存,删除缓存的做法,可能效率更高一些。但是也同样存在一些问题。
先删除缓存,再更新数据库。如果删除缓存成功了,更新数据库失败了,那其实对数据没啥影响,最多就是去读多一次缓存而已,不会对数据一致性有影响。
先更新数据库,再删除缓存。如果更新数据库成功了,删除缓存失败了,那会导致数据暂时不一致,而不会造成用户读到错误的数据。
从这点来看,删除缓存的方式比起更新缓存来说,是更好的一种选择。
但事实上,删除缓存的方式在高并发情况下也存在着一些问题。
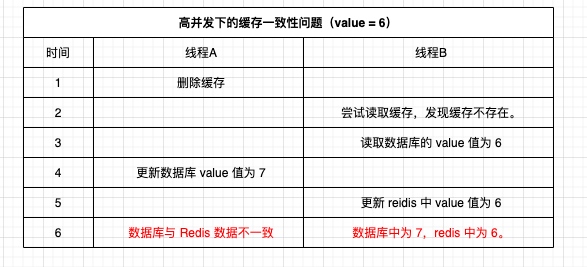
先删除缓存,再更新数据库。我们假设这样一种情况:当 A 线程去删除了缓存,而还没来得及去更新数据库,也就是在第一步和第二步中间时。线程 B 发现缓存没了,于是线程 B 去读数据库的值。此时 A 线程还没更新最新值,所以 B 读取到了旧值,于是线程 B 就把旧值放入缓存中,随后线程 A 更新了最新值。那么这个时候就会造成缓存与数据库短时间内不一致。
但实际上,这种可能性有多少呢?其实是微乎其微的。
首先,线程 B 会去数据库读取数据,一个很重要的前提是线程 A 删除了缓存。所以线程 B 去数据库读数据这个操作,必然是在线程 A 删缓存之后的。这一点很重要。
线程 A 删除缓存之后,肯定是立刻就去做下一步的操作,即更新数据库的值。而线程 B 肯定也是立刻去读取数据库中的值。这一点一般情况下,不会有太多的其他操作。所以根据前面线程 A 删除缓存,必定早于线程 B 去读缓存,可以知道:线程 A 去更新数据库,必定早于线程 B 去读取数据中的值。既然线程 A 更新数据库的值,会早与线程 B 去读取数据库中的值,那么一般情况下,线程 B 肯定是读取不到旧值的。
那么什么情况下会发生线程线程 A 更新数据值的值,慢于线程 B 去读取数据库中的值呢?我想到了几种可能,第一种:网络延迟,第二种数据库的主从延迟。
第一种,网络延迟。假设线程 A 是在机器 A 上的,线程 B 是在机器 B 上的。现在假设机器 A 跟数据库所在网络不稳定,比机器 B 与数据库的网络慢一些。那么线程 A 的请求到达数据库的时间,就有可能比线程 B 到达的时间慢,从而会发生这种情况。即线程 B 会读取到旧的值,而线程 A 也会更新成功。
第二种,主从延迟。即使网络没问题,但是因为做了读写分离,那么无论如何,都会有一个同步的时间差。那么在这个时间差里,即使线程 A 先更新了主库的值,但是线程 B 在主库更新之后和从库同步之前,去读取了从库的值,那么也同样会发生这个问题。
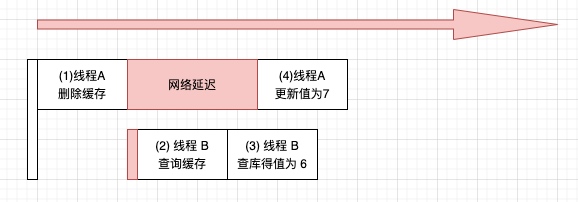
对于第一种网络延迟的情况来说,其网络延迟需要大于线程 B 查询缓存的时间,以及机器 B 到数据库机器的时间,以及其慢于线程 A 删除缓存的时间。一般情况下,这种可能性比较低,但是也不是不可能发生的,只是说可能性太低了。
对于第二种主从延迟的情况来说,其时间点要在主从延迟的时间范围内,并且与线程 A 更新值的同时去请求读取数据。相对来说,这种可能性也是有的。
总而言之,在网络延迟、主从延迟、高并发的情况下,删除缓存的方式确实会出现数据不一致的问题。
那如果我就是要求完全强一致性呢?
技术方案一般不能脱离业务实际,如果能容忍一定的数据延迟,并发量也不高,那么新更新数据库,再删除缓存是一种整体成本较低的方案。如果在某些领域,确实无法容忍一丁点的不一致,那么只能通过锁来实现了。
例如对于 value 的操作,在要读写这条记录的时候,对其进行 redis 加锁操作,并且不要使用副本读,这样就可以完全避免这种数据不一致的问题了。
有另外的方案,说是通过消息队列重试来实现,但这样做就太复杂了。本来发生的可能性就小,还要弄个消息队列,还要弄个消费者,这整套下来开发成本太高了。丢入消息队列也不一定能成功,又引入了技术复杂性。
此外还有说用 canal 实现数据库的监听,也是一样的问题,技术复杂度太高。得不偿失。